Metadata for publication-related Data Archives: As much as necessary and as little as posssible
Posted: August 1st, 2013 | Author: Sven | Filed under: EDaWaX | Tags: metadata, WP5 | Comments Off on Metadata for publication-related Data Archives: As much as necessary and as little as posssible In the course of our project we had to deal with a work package (WP5) in which we had to develop (or at least to choose) a metadata schema capable of describing and labelling publication-related metadata. Today I would like to summarize our approach and some of our thoughts for choosing an appropriate metadata schema.
In the course of our project we had to deal with a work package (WP5) in which we had to develop (or at least to choose) a metadata schema capable of describing and labelling publication-related metadata. Today I would like to summarize our approach and some of our thoughts for choosing an appropriate metadata schema.
I already characterised our approach in my talk at the IASSIST 2013 conference, but I would like to describe it more in-depth to start a discussion with researchers and the community, so feel free to comment.
In a first move we evaluated the data and further materials we found in the data archives of economics journals. These types of data we found within the journals’ data archives were seen as functional requirements, because the metadata schema should be capable to describe these data.
We focussed on a schema that should be capable to describe quantitative data – mainly because qualitative approaches are rare in Economics.
In addition we paid special attention to two other aspects:
- We did not want to develop a completely new metadata schema, because such a schema often is a stand-alone solution, which in many cases is not compatible to other systems and developments. Therefore we focussed on already existing metadata schemata that are already in use by numerous organisations.
- The efforts for researchers and editorial offices to fill in the necessary metadata should to be reduced to an essential minimum. A pro-rata between efforts and sufficient documentation should be kept. Furthermore the project favoured automated metadata creation especially in the case of authority files or thesauri.
Metadata Schemata for Research Data in the Social Sciences
In the social sciences there are well established metadata standards for the documentation of research data. Especially the DDI-standard (Data Documentation Initiative) provides all functionalities and is used and maintained by numerous initiatives

Data lifecycle (by DDI Alliance Structural Reform Group; adapted by Cole Whiteman, ICPSR)
and institutions. DDI3 is the “gold standard” for documenting data in the social sciences. The only issue with DDI3 is its complexity. Up to 846 metadata fields exist for the version 3.1. In our opinion this is way too much to persuade researchers to use this schema. Therefore we searched for alternatives that should nevertheless be compatible to the DDI schema.
Finally we found a useful and sound metadata schema used by the German research data registration agency da|ra. The aim of da|ra is to assign DOIs to social and economic research data.
The Version 2.2.1 of the da|ra metadata schema is not that much complex. It contains nine mandatory fields (and two of them are filled in automatically) and another 25 optional properties (with optional attributes).
Three levels of documentation based on the da|ra schema
 Based on the da|ra metadata schema we had the idea to define a few “levels of granularity” for descriptions of datasets. Each of these levels offers different functionalities and serves different purposes. The principal idea behind these levels is that researchers get to choose both their efforts for creating metadata and the functionalities their descriptions should serve.
Based on the da|ra metadata schema we had the idea to define a few “levels of granularity” for descriptions of datasets. Each of these levels offers different functionalities and serves different purposes. The principal idea behind these levels is that researchers get to choose both their efforts for creating metadata and the functionalities their descriptions should serve.
Below is a short description of each of these levels:
– Level 1: –
Purpose: Ensure citability
Advantages: The authors of publication-related research data could be cited in a standardized manner. This especially is important in regard to the question of incentives for sharing data.
Projected efforts: Only slightly more than a fistful of metadata fields are required.
Limitations: Very few information, “only” citations of datasets are enabled.
– Level 2: –
Purpose: Support findability
Advantages: Research data that is accompanied by this level of metadata can be discovered in disciplinary portals, by search engines or in data bases. Also linking data to (already published) publications is enabled.
Projected efforts: The 25 metadata fields with additional subfields are required. In total, researchers have to fill in less than 100 fields.
Limitations: Without an integration of authority files (e.g. ORCID, VIAF, etc.) it is not possible to expand the information available (e.g. affiliation, related work, other publications etc.). Also semantic web technologies aren’t supported.
– Level 3: –
Purpose: Ensure future reuse
Advantages: By integrating authority files (e.g. VIAF, ORCID, GND) a linkage across various data stocks is enabled (for instance it should be possible to link persons to their affiliations, to keywords or to special fields of research. Also future reuse of these (meta)data by semantic web technologies is possible.
Projected efforts: The 25 metadata fields with additional subfields are required. In addition all IDs for the different authority files must be submitted. In total, researchers have to fill in up to 100 fields.
Limitations: Even with this level it is not possible to include all information of the data lifecycle. Therefore replicability of published research is facilitated but cannot be ensured. Hence additional information is required – for instance all information that has been described in the replication standard published by Harvard Professor Gary King in 1995.
For the levels two and three, researchers indeed have to invest some of their time. Therefore it is very important to have some automated suggestion lists in particular for authority files in place to facilitate metadata creation. In addition it might also be a useful task for research librarians to fill in some of the required information.
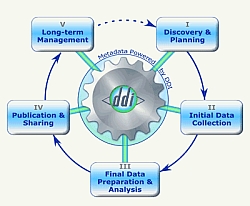 We also discussed a fourth “level of granularly”. The purpose of this level is to ensure replicability. The metadata that serves best for this approach is DDI3, because DDI is able to document all steps of the research data lifecycle. The efforts to document the lifecycle are significant but that’s not the problem, why we did not integrate this level in our application. The principal reason is that this level simply is not to realize for publication-related research data. This type of data typically is submitted to a journal at the end of research process and has already passed many steps of the lifecycle. At the end of a research process it is generally impossible to add those information subsequently.
We also discussed a fourth “level of granularly”. The purpose of this level is to ensure replicability. The metadata that serves best for this approach is DDI3, because DDI is able to document all steps of the research data lifecycle. The efforts to document the lifecycle are significant but that’s not the problem, why we did not integrate this level in our application. The principal reason is that this level simply is not to realize for publication-related research data. This type of data typically is submitted to a journal at the end of research process and has already passed many steps of the lifecycle. At the end of a research process it is generally impossible to add those information subsequently.
Whoops. A rather long post, but I hope it clarifies our approach a little more. Anyway feel free to comment or to raise questions!
Photo1 (top): “Metadata Madness wheel” by Musebrarian on flickr.com. License: CC-BY-NC-SA 2.0
Graphic1: by DDI Alliance Structural Reform Group; adapted by Cole Whiteman, ICPSR
Photo2:”Metadata” by Shira Golding on flickr.com. License: CC-BY-NC 2.0
Graphic2: by Data Documentation Initiative (DDI) on ddialliance.org
