Statistical software: its use and popularity in Economics
Posted: August 7th, 2017 | Author: Timo | Filed under: Report | Tags: economics, repositories, Software, Statistics | Comments Off on Statistical software: its use and popularity in Economics
by Christina Kläre & Timo Borst
During a four weeks project at ZBW’s Department for Information Systems and Publishing Technologies, we collected some publicly available information about statistical software packages being used in research in Economics. This work is inspired by a constantly updated blog post from Robert A. Muenchen, who examined information sources like job announcements, scientific articles, reports from IT companies, questionnaires, sales statistics from software textbooks, blogposts, forums, polls measuring popularity of programming languages, sales and download figures, or the frequency of software releases from software vendors. By means of these sources, we conducted the following data collections.
Statistical software in job postings
For collecting information on job postings, we looked up the job portal indeed.com, which was also the source for Muenchen‘s evaluations. Indeed.com has become the largest job portal in the US, outstripping monster.com in 2010. It provides an API interface, which requires a so-called ‘publisher account’. Since we did not apply for such an account, we conducted the following analyses by manual queries from the public web interface.
Simple search with names of software packages / programming languages on Indeed.com
By means of query terms for packages and languages possibly relevant in Economics and suggested by Muenchen, we counted the number of job postings only for open positions. The following figure depicts the occurrence of those statistical packages / programming languages in descending order, which returned at least 500 hits.
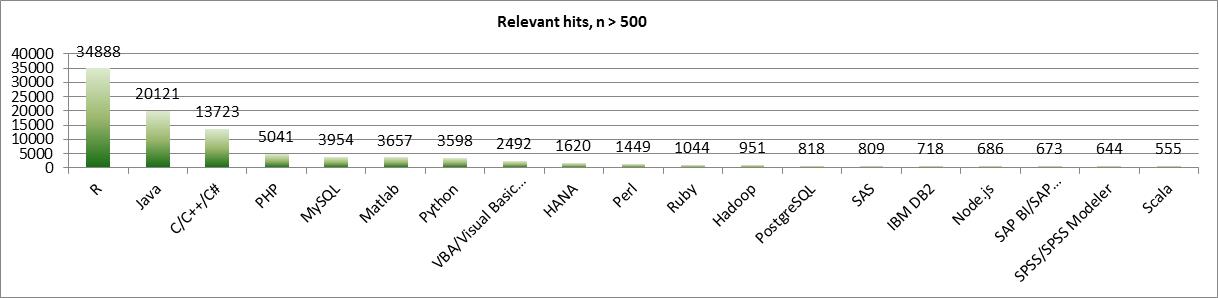
As a general conclusion, programming languages and proficiency in Open Source tools and platforms are obviously required in job market. In some cases there are multiple skills required, e.g. expertise in Matlab and R, or in Python and R.
Filtering according to general scientific staff on Indeed.com
Since this analysis also includes non-researcher positions, we had to filter the results according to positions for scientific staff (blue column). As a consequence, the hit rate decreased massively (with the academic market only forming a small fraction of the general job market), hence in the following chart any hits for statistical packages / programming languages are listed. From this set, we selected the hits from universities and institutes as the main scientific employers (red column).
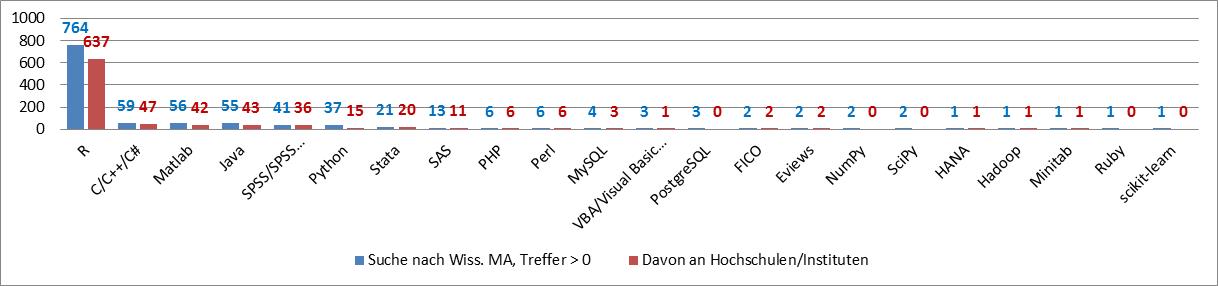
Here the popularity of R is striking, as is the preference of some programming languages (C, C++, Java, Python) in addition to statistical packages. It must be considered that, in many cases, the description of a job position in the academic realm contains both packages and languages.
Narrowing down according to researchers in Economics on Indeed.com
Since the preceding results do not yet refer to the particular scientific community in Economics, again we filtered the results accordingly:
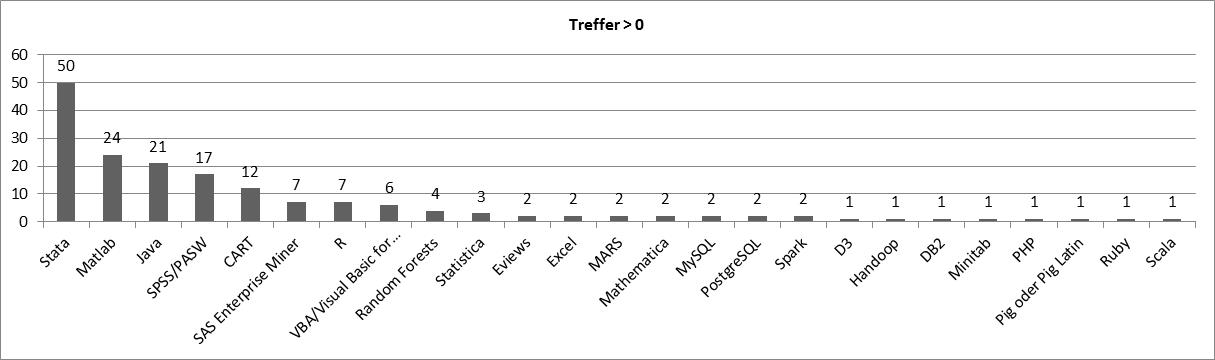
As a bit of a surprise, popular statistical packages like R, Stata, SPSS or Matlab are predominant, while programming languages are less explicitly required. A reason for this might be that faculties in Economics require rather skills in (licensed) packages than in generic languages. A strong requirement for R skills is evident due to the fact that this package is Open Source (hence independent from a faculty’s purchasing strategy) and a proof-of-skills for other statistical programs like Stata or Matlab. As with any other required skills, we often found multiple options in the job offerings.
Academic papers
For academic papers, two of the largest Open Access repositories resp. search portals in Economics were chosen, EconStor and EconBiz.
Simple queries with names of software packages in EconStor
With query terms denoting statistical packages or programming languages relevant in Economics, we received results on bibliographic metadata and/or fulltext search. The following figure depicts the hit rate. We randomly investigated if the query really matched the name of a statistical package or a programming language, and not e.g. an abbreviation or acronym introduced by the author.
Software packages not listed in Muenchen were not queried. The following figure lists statistical programs or programming languages with decreasing hits and a hit rate >= 1, with all results taken from EconStor documents.
Stata and Matlab are the most popular software packages in EconStor publications, which primarily are Working Papers or Preprints. We did not check the corresponding access restricted article publications resulting from former Working Papers or Preprints, it would mean an evaluation of its own to compare the replicability of journal articles and their related preprint version.
Queries for „regression analysis“ in EconStor
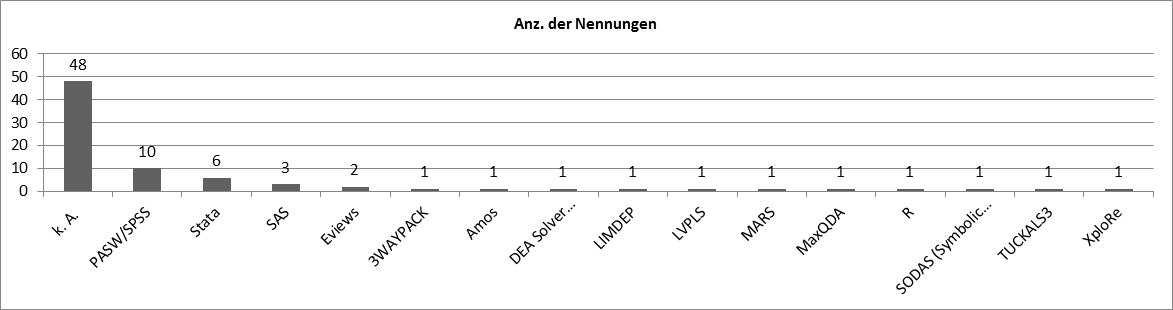
To provide a deeper insight into the use of statistical software in academic papers, we conducted a query on one of the most common statistical operations, „regression analysis“. 65 documents were found in EconStor (metadata or document), and each publication was checked for information on identifier/link, authors, title, year, document type, language, software and research method (e.g., for what purpose the software was used, e.g. regression or descriptive analysis)
As a bit of surprise, 48 from 65 publications did not mention the software or programming language used for the statistical calculations or results, which lies in some coincidence with other studies stating that only a minority of published research is replicable. Moreover, it is remarkable that in first place commercial software packages like SPSS and Stata were mentioned resp. used, while the explicit use of R could only be traced once. In addition to the list of Muenchen, some accidental use of other statistical programs could be discovered.
The location of the software package shows some evidence on the methodological relevance of the statistical program. E.g., while explicitly citing a teaching book or a research paper reveals some sensitivity for good scientific practice, other authors just expressed their thanks to a colleague for providing the software code within a footnote. Sometimes the software used is mentioned multiple times, hence resulting in a higher hit rate than the following figure depicts.
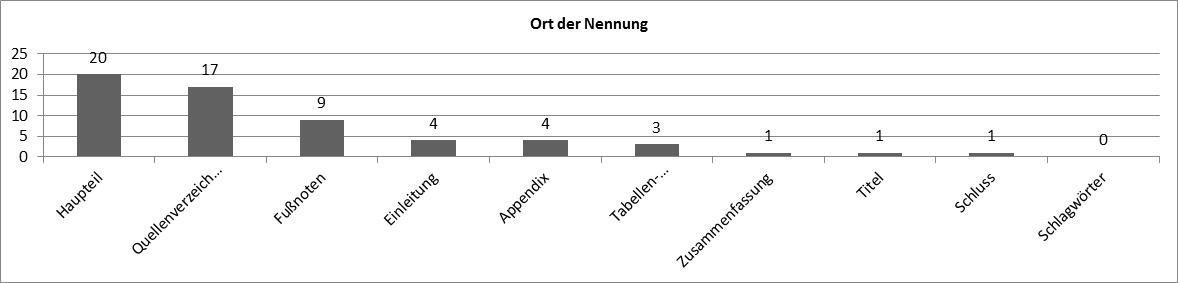
Lastly, if a software is already mentioned in the main part of a document, in most cases within a methodological section the specific version is given. In contrast, the least prominent representation of a statistical software is to place it in a rather marginal sectionsof a paper like the appendix or image/table captions, or to depict the software just by its logo.
Until now, there is no information on statistical software in the JEL classification, nor in the Standard Thesaurus for Economics (STW). Authors hardly characterize their approach by means of free keywords for statistical programs or programming languages. It would be a consideration to extend the STW with concepts for statistical packages, so they can be indexed in the future.
Simple queries with names of software packages in EconBiz
Likewise to EconStor, we also conducted a query for statistical software and programming languages in EconBiz to take other Open Access and access restricted publications into account, the latter on the level of their metadata including their abstract. The following figure shows the hit rate for the 15 packages/programming languages with the highest hit rate in descending order.
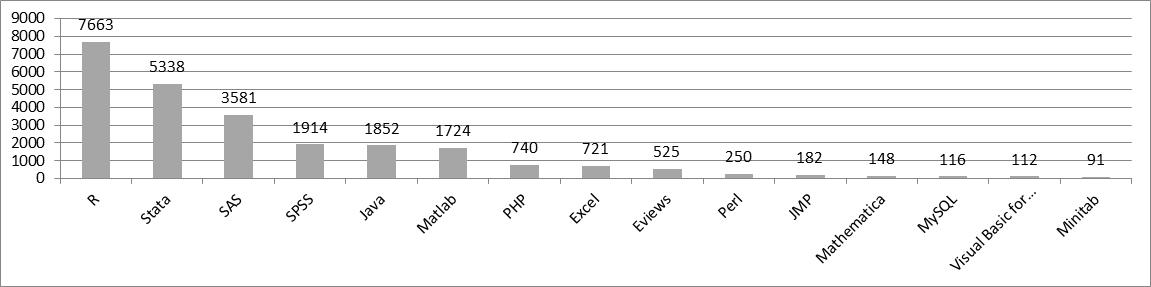
Here, R is the most used or popular statistic package, followed by the commercial Stata.
Queries for „regression analysis“ in EconBiz
Likewise to the querying of EconStor documents, we also conducted a query on „regression analysis“ on the EconBiz index. With a total hit rate of 4072 documents resp. their metadata, we investigated 26 results more into detail (with nine publications as open access, and 17 as closed access). Likewise to the result for EconStor documents, 14 publications do not mention the software used, while six of them mention Stata and Excel, SPASS and z-Tree once. Acknowledgements for software were the list of references (six papers), the body (five papers), footnotes (four papers), summary/abstract (one paper), introduction (one paper) and table/image caption (one paper).
Software packages in data repositories
Another source for analyzing the use of statistical software are academic data repositories. Although these repositories resp. their metadata schemes do not necessarily require the acknowledgement of the software used to generate or process the data, they can provide additional information and insights.
The following table shows the results of querying DataCite with our terms. Non-roman fonts like the Arab were not considered. If results exceeded 100 hits, only a sample was checked. By extending the results from DataCite (first column) with the results from two national Data Centers (RWI and GESIS), we tried to explore the amount of German datasets in Economics. Overall, there were over 2.5 Million datasets registered in DataCite (as of August 2016).
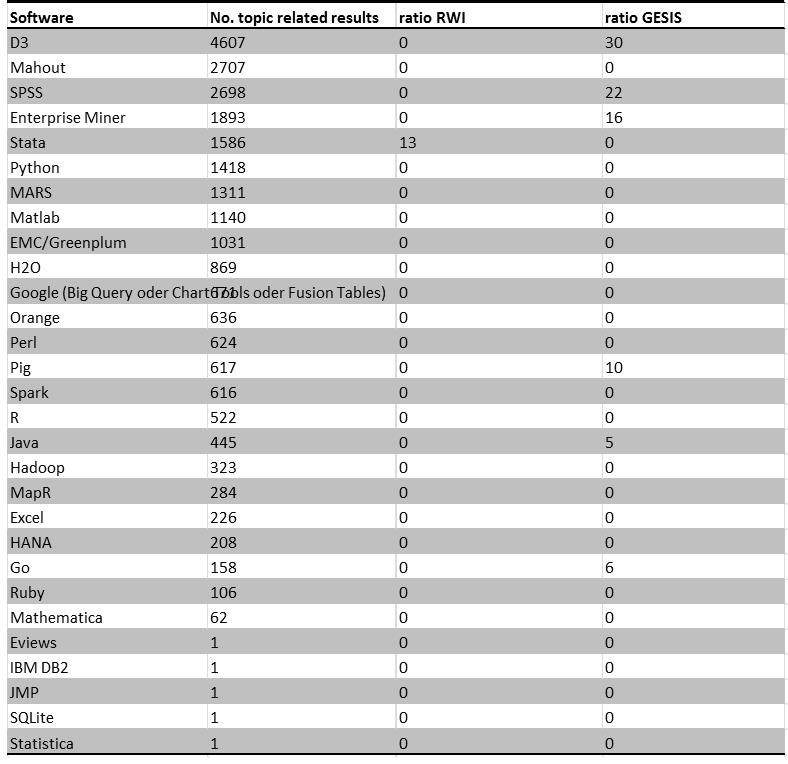
The table captures only software which was found at least one time. According to this criteria, we found statistical data related to SPSS, SAS (Enterprise Minder) and Stata, whereas R seems to be less documented. In a second step, we had a closer look at the metadata of repositories from RWI, GESIS and the German FDZ SOEP.
![]()
Figure: Results from data repositories from SOEP, RWI and GESIS listed with different statistic file formats
![]()
Figure: Results from data repositories from SOEP, RWI and GESIS listed according to their documented “Analysis System(s)”
Overall we found 88 data sets from RWI, 6.808 data sets from GESIS (among them 31 checked by us), and 29 data sets from FDZ SOEP. Partially, there were more data formats and statistical programs mentioned, resulting in a coverage of more than 100%. However, for the sake of better comparing the different repositories, we retained the percentage number.
It should be noted that only proprietary data formats were provided, Open Source packages like R were not mentioned even in the category “Analysis System(s)”. Moreover, only the GESIS repository explicitly documents the statistical package used, whereas the repositories from FDZ SOEP and RWI only provide information about the data format (generated by statistic programs). However, to derive individual software from data formats still can be highly ambiguous, for most of this software can produce e.g. CSV data outputs.
Software packages in GitHub
Furthermore, we took GitHub as a platform and community for software projects also in science and research, again querying with our terms. Among the relevant indicators we identified
- total number of repositories
- maximum number of forks,
- number of pull requests from the repository with the highest number of forks,
- number of commits from the repository with the highest number of forks,
- maximum number of stars,
- number of pull requests from the repository with the highest number of stars, and
- number of commits from the repository with the highest number of stars

Figure: Activities on statistical packages in GitHub
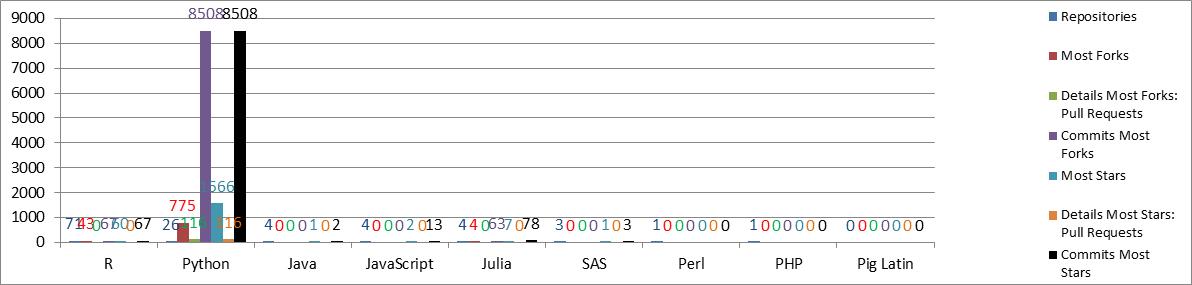
Figure: Activities on programming languages in GitHub
It is remarkable that R as the most prominent Open Source project with a large developer community is supported by many Git repositories, forks and pull requests, but that Matlab as commercial software is linked to many repositories as well. Two other programs – Stata and SPSS – seem to be less interesting and less generic in terms of reaching a wider developer community, with Matlab presumably used outside of Economics and Social Sciences, whereas Stata is rather affiliated to Economics and SPSS to Social Sciences.
With respect to the retrieval of programming languages used in Economics, we filtered the results by means of the search term “econometrics”, with the largest number of commits for Python, but with less Git repositories than R.
Statistical Software in replication studies
Another source for investigating the use of statistical software in Economics are replication studies, which are explicitly supported by some journals providing data and code, e.g. Review of Economics and Statistics or Journal Data Archive.
As a general observation, the topic of replication of research results is highly debated, often addressed as “replication crisis”. Primary data, imported data, metadata, syntax files and ReadMe files are required for the purpose of replicability, but – perhaps even more important – also for the purpose of ongoing research and creation of new knowledge.
Reasons for refraining data might be:
- Journal policies which require their authors to submit in repositories preferred only by journal publishers,
- the author’ s reluctance to explicitly work on data just for the purpose of publishing and sharing (while this is normally covered by the publication),
- the current publishing market, which still does hardly serve replication and calculation workflows.
In that sense, data repositories should not only provide data resp. their metadata, but also the code and scripts responsible for processing the data.
Conclusion and Outlook
Our data evaluations show that in the academic world with all its facets – from data and software management to publishing and job profiles – the statistical packages Stata, R, SPSS and Matlab seem to be preferred. Our methodological approach is improvable, since we were heavily dependent on querying ambiguous strings, rather than relying on e.g. explicit documentation or citing of statistic programs as suggested by the Software Citation Principles, the latter yet to be established in the context of a more conscious research data management. It is desirable to repeatedly conduct those studies we suggested, while benefitting from more sophisticated techniques from data and text mining.
All figures are licensed under Creative Commons BY 4.0
