Adapting CKAN for Open Research Data
Posted: September 3rd, 2013 | Author: Sven | Filed under: EDaWaX | Tags: ckan, prototype, Software | 6 Comments »![]() One aim of EDaWaX is to develop and implement a web-platform prototype for a publication-related research data archive. We’ve chosen CKAN –an open source data portal platform– as basis for this prototype.
One aim of EDaWaX is to develop and implement a web-platform prototype for a publication-related research data archive. We’ve chosen CKAN –an open source data portal platform– as basis for this prototype.
This post describes the reasons for this decision and tries to give some insights in CKAN, its features and technology. We’ll also discuss these features both in regard to our special use case and to the suitability for research data management in general.
Before you proceed it might be useful to have at least a short look at an article that covers a similar topic and does it far more extensively than this blog post. It’s written by Joss Winn and is titled Open Data and the Academy: An Evaluation of CKAN for Research Data Management. The paper is available on GoogleDrive so others could comment or even add to the article. I’m also mentioning Joss’ paper to show that there is already an ongoing discussion —for example in this mailing list thread— about how to adapt CKAN, which is at the moment mainly used for government data, for research data management.
This post focuses on our special EDaWaX perspective and does also provide some more technical introduction (installation, writing extensions, using the API etc.). In addition we describe our own CKAN extensions that add basic theme customisations and custom metadata fields.
We hope this will be useful for those who are looking for a decent solution for a research data repository and have heard only a little or (most probably) nothing at all of CKAN yet.
EDaWaX criteria for research data archive software
We won’t go in detail about the EDaWaX project here. In short, EDaWaX is looking for ways to publish and curate research data in economics. Our focus is on publication-related data, meaning especially the data authors of journal papers have used for their articles. One objective of the project is the development of a data archive for journals using an integral approach.
Our to be developed web application should demonstrate some features the EDaWaX studies revealed to be important for replication purposes. We evaluated several software packages dealing with data publishing and had only a few very general, but fundamental criteria for the software:
- Open Source This is a fundamental principle for us, but there are also practical reasons for this. We want to be able to modify and extend the software, and we would like to share our extensions.
- API (reading and writing) This is quite important for a modular and flexible infrastructure. We also want to provide integration packages for other systems (CMS or special e-journal software). We think that research data must not just be stored in, perhaps closed, ‘data-silos’, but should be accessible and reusable as much as possible. An API opens up a lot more possibilities for this purpose.
- Simple User Interface We are mainly targeting authors and editorial offices who don’t have time, resources and ‘knowhow’ to learn and use complicated UIs and workflows. This is also important for lowering the general barriers for publishing research data.
- RDF metadata representation We are aware that this might be a somehow ‘avant-garde’ criteria. But we predict that it will be more and more important in the near future to have a general, linkable and machine readable metadata interface, so our research data can be used and adopted most widely.
The main ‘opponents’ of CKAN in this small ‘contest’ were Dataverse and Nesstar. And while both are well established platforms dedicated especially to research data (which CKAN is not) they both did not met most of our criteria. Nesstar is proprietary, not open software, you have to pay for the server component, and the only way to upload data is the use of the so called ‘Publisher’, a Windows-only client. That’s a No-Go for us. Dataverse’s main problem compared to CKAN (and besides that it is an unfriendly java-beast of software 😉 is the lack of a decent API. At least there’s a reading API by now (since March 2012) but you cannot use it to upload data. So, in the end it was no question which software we would choose: CKAN. Let’s see in detail why.
What is CKAN?
CKAN –an abbreviation for “Comprehensive Knowledge Archive Network”, which does not exactly express its actual usecases today– is an open-source (check) web platform for publishing and sharing data. Written in Python, it offers a simple, nice looking, and very friendly userinterface (check) and provides by default a RDF metadata representation for each dataset (check). The feature that, in our view, makes CKAN really outstanding is its API, which allows access to nearly every function of the system including writing and deleting of datasets (check; more on that later).
CKAN has many, many more features that could be listed here, including harvesting, data visualisation and preview, fulltext and fuzzy search, and faceting. It is widely used, mainly in the field of open government data, where it has become a de facto standard software. CKAN powers the national open data portals of the UK, the USA, Australia or the EU, to name only a few and well-known. The CKAN website has an impressive list with all known production instances.
The very active development of CKAN is led and organised by the Open Knowledge Foundation (OKFN). There are around ten people at OKFN who are mainly working on CKAN, most of them developers, and in addition at least 30-40 developers are contributing actively.
If you want to contribute to CKAN or develop an extension you should subscribe to the developer mailing list. There’s also a general discussion list, and if you want to use CKAN for research data management (and in the end that’s what this article is all about) please immediately subscribe to the quite newly established and already mentioned list ckan4rdm.
CKAN’s source code can be found at github. It is written very cleanly (forced by clear coding standards). As a mediate experienced Python developer you won’t have major difficulties in understanding the code.
If you just want to test the frontend, e.g. the user interface of CKAN you don’t have to install it yourself. OKFN is running the public open data portal datahub.io, where you can register and upload some data. The portal is not only for testing purposes. For example, all the RDF data of the Linked Data cloud is registered there. There’s also a ‘pure’ demo site that gives you a first impression.
However, if you’re really considering CKAN to power your open data portal you should of course install it yourself.
Installation
Before you start to install and use CKAN please have a look at its extensive and excellent documentation. We will only give some hints here, to give you a starter.
If you have decided to give CKAN a try you have two install options. If your machine runs a 64-bit Ubuntu 12.04 you can try to install all needed packages via apt-get. The package installation will do all necessary basic configurations for you, so it might be more convenient. However, this method also involves some lack of flexibility, so we would not recommend it. Moreover, if you perhaps want to develop your own CKAN- extension (more on that later) or use another OS platform, you must use the second method and install CKAN from source. I didn’t found that to be too difficult and, again, if you have some experience as developer it will be no real problem. In this scenario CKAN will be installed via git and pip in a virtualenv, which you are most probably already be familiar with. The application then is ran with paster. Under the hood CKAN uses the Python framework Pylons (which has now merged with another framework and is called Pyramid; but that’s another story).
In addition to the core package of CKAN you will have to install and configure some packages that CKAN requires. Nothing fancy here, though. CKAN uses Postgresql as database, and for searching and indexing it relies on Solr, which involves the installation of a Java JDK and a java application server like Jetty or Tomcat. It’s worth mentioning that you can run CKAN without Solr, but you’ll lose a lot of advanced search functionality like faceting for instance. The same goes for the database. Besides the almighty Postgresql you can also use the lightweight SQLite. This is quite handy for testing purposes or for development, but not recommended and supported for production installations.
API
As mentioned before, we think it’s the API that makes CKAN really outstanding. “All of a CKAN website’s core functionality (everything you can do with the web interface and more) can be used by external code that calls the CKAN API”, as the documentation states. And that’s true. You can
- get all sorts of lists for packages, groups or tags;
- get a full metadata representation of any dataset or resource (which is the actual data or file);
- do all kind of searches you can do with the web interface;
- create, update and delete datasets, resources and other objects. I’m emphasizing this because it’s really a killer feature, which enables you to develop your very own application based on API calls to an external CKAN installation. It makes, for example, mobile apps possible. Or you can write plugins for your local CMS, journal system or whatever.
From a programmer’s perspective this is just great, great, great. And even regarding our focus, open research data management, it enables a lot more usage scenarios than a simple webportal with a closed, proprietary database would do.
And in fact, it is quite easy to use the API. There are client libraries for any common web programming language (Python, Java, Perl, PHP, Javascript, Ruby), so you don’t need to write the basic functions on your own. A very simple Python script like the one below is sufficient to upload a file to a CKAN instance:
import ckanclient
CKAN = ckanclient.CkanClient(api_key=<your_CKAN_api_key>,
base_location=<url_of_CKAN_instance/api>)
upmsg = CKAN.upload_file(<your_local_filename>)
print upmsg #this is not necessary ;-)For demonstration and testing purposes we’ve developed a small sample application. It was built with the Pyramid framework and can completely manage the datasets of a certain group at an external CKAN instance. The demo pics show the list of the packages and a form to create a new dataset. Since this instance is for developing and evaluation purposes only it’s not public, but hopefully the pics will give you a first impression what’s possible.

Custom application using the API: list of packages

Pyramid app: add_form
It’s worth mentioning, that of course writing your own application around the CKAN API also allows you to simply add features CKAN might not have. So, for instance, the little red X mark at the right side of all packages (screenshot #1) enables a direct deletion of the package. That’s something CKAN’s UI does not offer by default.
OK, you’re saying, I got it, the API is great. But I don’t want to programme an external application. I just want to stick with the original platform, but I need another look, and even more special functionalities. So, is CKAN extensible?
Short answer: Yes.
Long Answer: Writing Extensions
Adding a custom theme or functionality is done with so called extensions. CKAN extensions are ordinary Python packages containing one or more plugin classes. You can create them with paster in your virtual environment.
paster create -t ckanext ckanext-mycustomextensionNote that you must use the prefix ckanext-, for otherwise CKAN won’t detect and load your package. You then have to install it as a develop package in the Python path of your virtual environment. That’s done the usual way with
cd <path_to_your_extension>
python setup.py developor even
pip install -e <path_to_your_extension>Please refer to the docs for a detailed description on writing extensions. Basically you’d use the so called PluginToolkit and a whole bunch of interface classes with which you can hook into CKAN core functionality with your own code. You will most probably also need to overwrite some Jinja templates, especially if you want to create a new look for your portal.
CKAN provides some basic example extensions that will quickly give you a rough understanding of how the plugin mechanism works. In addition there are many (many!) CKAN extensions already available. You can browse them at github.
So, what are the extensions we are developing for EDaWaX?
EDaWaX extensions and implementations
Basically we are working on two extensions for EDaWaX at the moment. The first one, called ckanext-edawax, is mainly for the UI. It tweaks some templates and UI elements (logo, fonts, colors etc.). In addition it removes elements we do not need at the moment, like ‘groups’ or facet fields, and it renames the default ‘Organizations’ to ‘Journals’, since this is our only type of organization and we’d like to reflect this focus. We will also add new elements, like proposed citation in a dataset view. You can get the idea of the prototype with these screenshots.
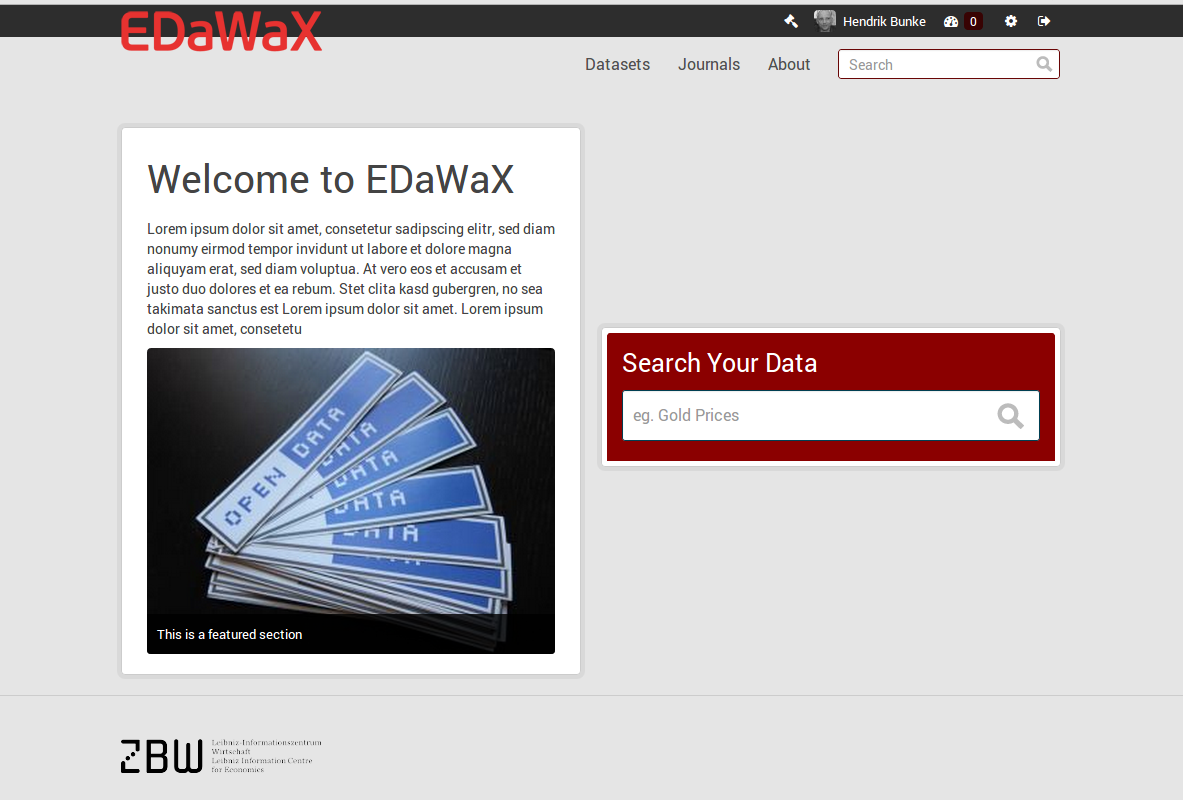
EDaWaX custom frontpage
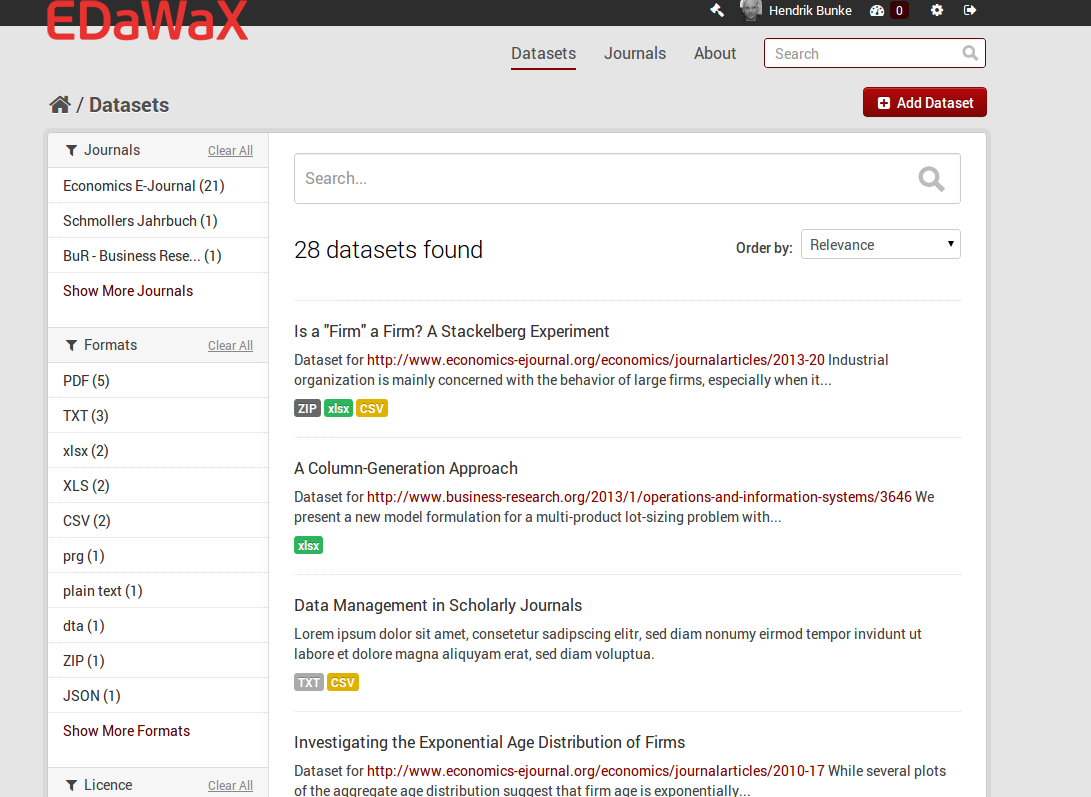
EDaWaX datasets view
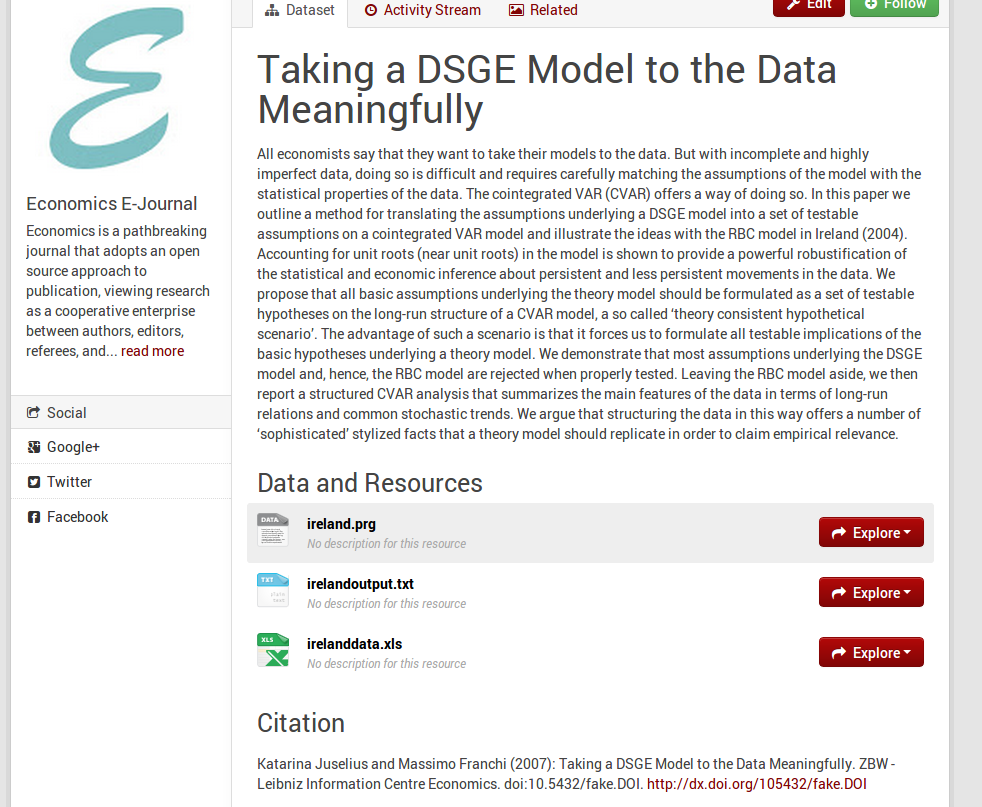
EDaWaX single dataset view
Our second package, ckanext-dara, relates to metadata. CKAN offers only a kind of general and limited set of metadata for datasets (like title, description, author), that does not reflect any common schema. You can, nevertheless, add arbitrary fields via the webinterface for each dataset. But that’s not schema based. The approach of CKAN here is to avoid extensive metadata forms, that might restrict the usability of the portal, and also not to specialise on certain types or categories of data, like, you name it, research data. Dedicated research data applications like Dataverse do have an advantage here. Dataverse’s metadata forms are based on the well-known and very extensive DDI schema. CKAN is not originally a research data management tool, and the lack of decent metadata schema support is one point where this hurts. However, this more general approach as well as the plugin infrastructure (a feature, that Dataverse does not offer, AFAIK) enables us to customise the dataset forms, add specific (meta-)data, and to guarantee compatibility with a given schema. For EDaWaX this will be the da|ra schema, which itself is partially based on the well-known, but less complex data-cite scheme. The german based da|ra basically is a DOI registration service for social science and economic data. Since we will automatically register DOIs for our datasets in the CKAN portal with da|ra it makes perfectly sense that we use their schema (which we must do anyway when submitting our metadata).
ckanext-dara is the CKAN-extension where all the metadata functionality as well as the DOI registration will be added. It is also planned to publish this package as Open Source on github. So far the development has concentrated on extending the standard CKAN dataset forms with da|ra specific metadata. The problem here is the conflict between usability and the aspiration to get as much metadata as possible. You know, we are working in a library. For librarians metadata is important. Very important. You can say, that librarians do think in metadata. We want every single detail of an object to be described in metadata, if possible in very kryptic metadata. Since metadata schemes are often (if not always) created by librarians they tend to be kind of exhaustive. The current da|ra scheme knows more than 100 elements, which is only a small set compared to DDI that knows up to 846 elements. Now please imagine you’re a scientist or the editor of a scientific journal who is asked to upload research data to our CKAN based platform. Would you like to see a form that asks for ~100 metadata elements? You’d certainly not. Chances are good that you would immediately (and perhaps cursing) leave the site and forget about this opendata thing for the next two decades or so.
To deal with this conflict we are following a twofold approach. First, we are dividing the da|ra metadata scheme into three levels reflecting the necessity. Level 1 contains very basic metadata elements that are mandatory, like title, main author, or the publication year. These fields of level 1 correspond to the mandatory fields of the DataCite metadata schema. For this level we only need two or three new fields in addition to the ones that are already implemented in CKAN. Level 2 contains elements that are necessary (or perhaps better: desirable) for the searchability of the dataset or special properties of it. And finally Level 3 reflects the special metadata we need to ensure future reuse by integrating authority files. By integrating these authority files it should be possible to link persons to their affiliations, to articles, research data, to keywords or to special fields of research.
Second, we will try to integrate these different levels of metadata as seamlessly as possible in CKAN’s UI. The general idea behind this is to give users the choice which metadata functionalities they would like to equip to their data. To achieve this we collapse the subforms for level 2 and level 3 in the dataset form with a little help of jquery. The following screenshots give you an idea. Please note that this is an early stage of development and nothing’s finalised yet. We have not implemented level 3, yet. However, you can see that the form for level 2 (as well as later for level 3) is collapsed by default, so the “quick’n’dirty” user won’t have to deal with it if she does not want to. We are still thinking, however, about the motivation/information text and its presentation.
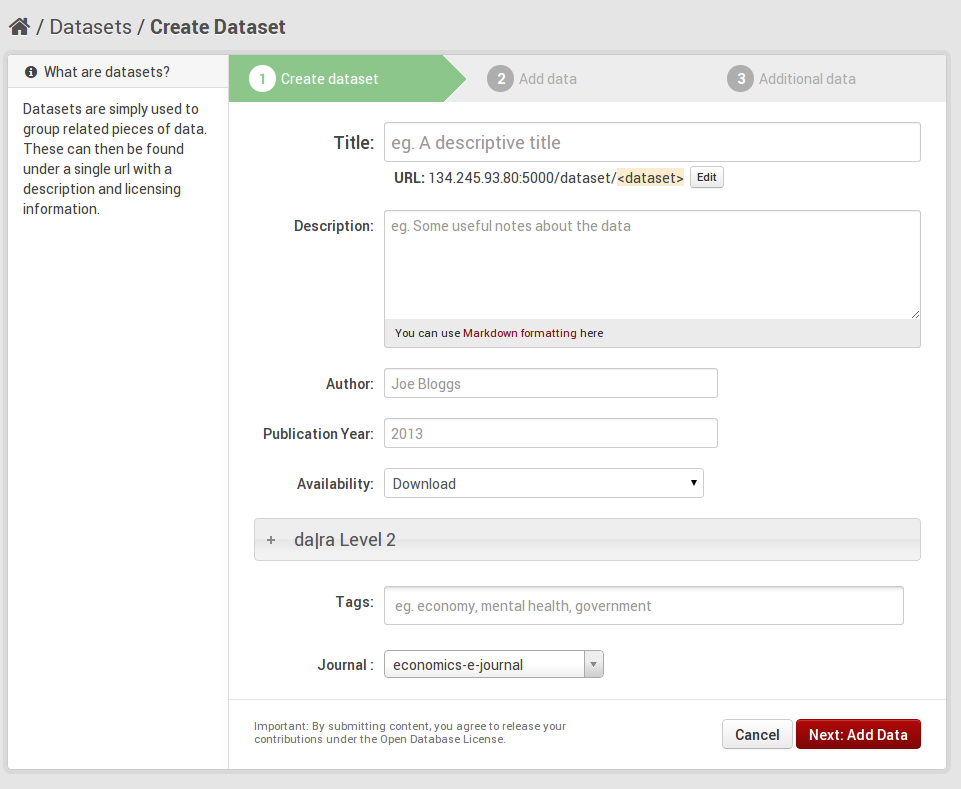
ckanext-dara addform
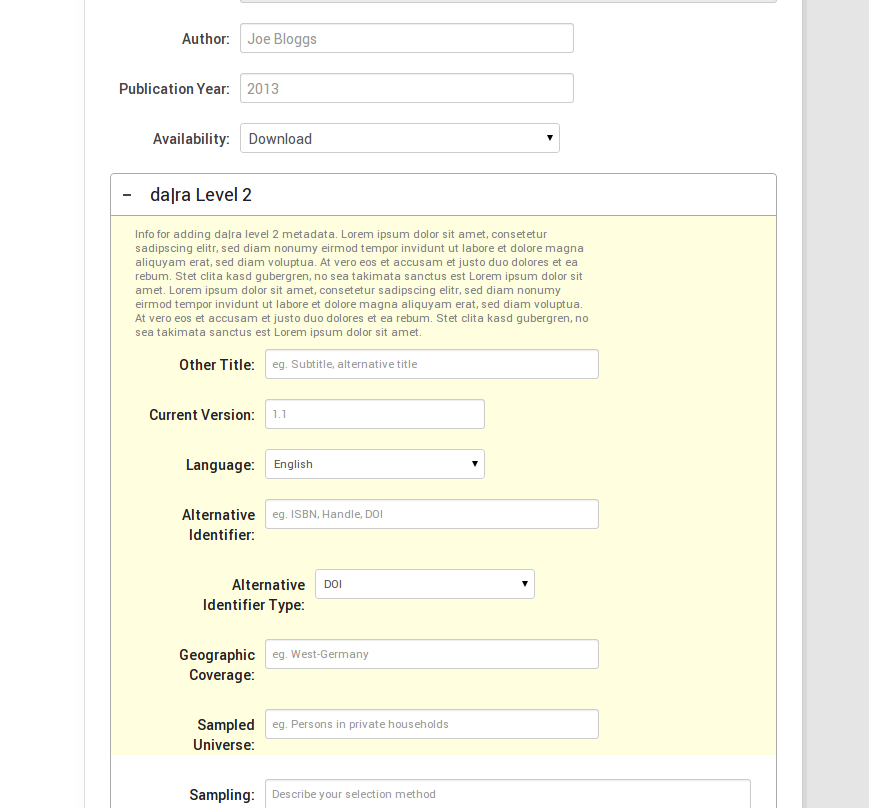
ckanext-dara addform extended
Journal CMS addon
In addition to building the opendata portal itself we are planning to develop an addon for an existing E-Journal, that uses the CKAN API. This will be done for the CMS Plone, which is the base of the E-Journal ‘Economics’. It should mainly be a testcase for usability of the CKAN API for editorial offices. Editors of ‘Economics’ have some experience with Dataverse (and are not always happy with it) so we do have a very good setting here. Generally we consider the integration in third-party systems to be very important for the acceptance of CKAN as a repository for publication-related research data. Users should not be bothered with having to use two (or even more) different systems for data and text. This approach also gives the maximum of integration for data and articles. Dataverse, for example, will develop such functionalities for OJS (Open Journal System) presumably within the next two years. CKAN has kind of a head start here due to its great API, but I think we need to popularise CKAN in this respect, so this package will be developed as a ‘proof-of-concept’.
Conclusion
At least for our usecase in the EDaWaX context CKAN has proven so far to be the best available solution for an open research data portal. Due to its current focus on open government data, it might show some desiderata regarding the use for research data. CKAN is focused on data publishing, not data curation. This shows up exemplarily in it’s very basic support of metadata. But as we’ve shown CKAN has two fantastic features –the API and the plugin mechanism– that facilitate the development of extensions and third party apps for usecases in the field of research data. Development in this direction has started already (not only in our project) and it’s foreseeable that those efforts will be ramped up soon.
So, if publishing of open research data is on your schedule please consider using CKAN and give it a serious try. It’s worth it. If you have any questions, comments or criticism please leave a note in the comments section. Please feel also free to write an email to h.bunke <at> zbw.eu in case you have a more specific question.
Image: Open Knowledge Foundation. Licensed under Creative Commons Attribution ShareAlike (Unported) v3.0 License.

Can you say a bit more about how you’ve added the extra metadata fields? You wrote that CKAN doesn’t use schema documents. Does that mean that the fields are hard coded in Python (and you would have to extend them using Python too)? Could this Python code be generated from an XML schema document using XSLT?
I’m interested because this is almost certainly something that we’ll be wanting to do if our institution starts to use CKAN.
I am very keen on learning how you have implemented additional metadata based on a schema. We have a need to enforce additional metadata for different data types. Hope to see your implementation on github soon.
Thanks.
Metadata fields are added with one of the mentioned plugin interfaces (IDatasetForm). The actual necessary code for this is very small and basic. Please have a look at the example https://github.com/okfn/ckan/blob/master/ckanext/example_idatasetform/plugin.py to get the idea.
So, yes, the fields are hard coded in Python. But, of course, this code could also be generated at runtime. In our package it is at the moment, for simplicity’s sake, not derived from a XML file but from a Python dictionary that contains only two or three keys for each metadata field. To build the actual necessary code for the fields I’m just iterating over this dictionary. I can see no reason why this would not be possible with a XML file (Python has some pretty good XML parsers, and I would not recommend using XSLT for this), and actually that’s what we are planning for the next project stage. It just needs more development efforts and time. And in addition you’ll have to generate the code for the templates.
[…] For the development of a publication-related research data archive, we chose CKAN, an open source data portal platform, as foundation for our prototype. […]
Thanks for this informative article!
We have also adopted CKAN as the data repository service (not yet released) for the Deep Carbon Observatory project . In our original vision we planned to upgrade CKAN’s metadata model — in short, to have more of an ontology-driven, object class based system of metadata — but then we realized we were turning an apple into an orange.
Instead we decided to embrace VIVO as an object creation and metadata management “front end,” using CKAN only as a repository for depositing the manifestations of the objects as required. This is very power, because it allows us to persist metadata relationships about every entity in the project, real or conceptual, and relate to real data as required. We have integrated our Handle System-based identifier system with VIVO, so every new object in our VIVO gets a DCO-ID…
We will be writing about all of this soon. Look for me at the upcoming Research Data Alliance plenary if you’re interested in learning more…
If you are interested in using CKAN for managing research data, you may also be interested in the most recent user manual of our CKAN-application.
Kind regards
Sven (project manager EDaWaX-project)