Posted: July 31st, 2019 | Author: Sven | Filed under: Uncategorized | Tags: Replication, resource | Comments Off on The ReplicationWiki – an important resource for economists
The ReplicationWiki gives
information about empirical studies in the social sciences. It offers a
database containing empirical research and shows where to find program codes
and data, which methods were used and which software.
One can search for keywords,
authors, databases or journals.
In particular it lists so far 515 replications, 20 corrections, and 10 retractions;
including information about the results of replications. 3,388
studies are already covered. The pages have been accessed more than 5.9
million times.
It helps
researchers see which results have already been revisited. For instructors it
helps to identify practical examples for which data and code are available in a
software format that is accessible to their students. In our experience it
helps to motivate students to study quantitative methodology and to approach
published results with healthy scientific scepticism.
The
ReplicationWiki also offers information on literature
on the topic of replication, on journal
policies on data availability, on data
and software repositories and on projects
that employ replication in the different social sciences.
Originally the
Wiki was founded for economics. By now a number of studies from other social
sciences were included, in particular political sciences and sociology. It has
been cited
as a project to follow also from fields like empirical law and empirical
archaeology. Contributors are welcome! As the project is set up as a wiki
website, any researcher can participate. After registration
with one’s real name and an institutional email address one can for example add
replications or studies that should be replicated, announce relevant events,
discuss
suggestions how to improve the project, set up one’s own user page and vote
on which studies should be replicated. Registrations just to signal support for
the project are also welcome. The ReplicationWiki is meant for an international
audience and is therefore set up in English. Adding studies in other languages
to its database is however welcome, and users can write in their own language
on their user page to help others find them.
A detailed
description how to add further studies can be found here: for replications
and replicated studies and for studies
that have not yet been replicated.
Further reading: ReplicationWiki – Improving Transparency in the Social Sciences, Jan H. Höffler, D-Lib Magazine, March/April 2017, Volume 23, Number 3/4, doi: 10.1045/march2017-hoeffler.
Picture: Image by Jan Vašek from Pixabay . License: click
Posted: October 23rd, 2018 | Author: Sven | Filed under: Data Sharing, EDaWaX | Tags: replication studies | Comments Off on New paper highlights replication studies in economics
 Four researchers associated with the former project EDaWaX have recently published a new research article entitled “Replication studies in economics – How many and which papers are chosen for replication, and why?” The article, written by Frank Mueller-Langer, Benedikt Fecher, Dietmar Harhoff and Gert G. Wagner, sheds light on replication practice in empirical economics. The article can be found here (published in Research Policy under a Creative Commons license). Here, they provide a brief overview of the paper:
Four researchers associated with the former project EDaWaX have recently published a new research article entitled “Replication studies in economics – How many and which papers are chosen for replication, and why?” The article, written by Frank Mueller-Langer, Benedikt Fecher, Dietmar Harhoff and Gert G. Wagner, sheds light on replication practice in empirical economics. The article can be found here (published in Research Policy under a Creative Commons license). Here, they provide a brief overview of the paper:
Read the rest of this entry »
Posted: April 16th, 2018 | Author: Sven | Filed under: EDaWaX, journals | Tags: data archives, Data Policies, Linking Data and Publications | Comments Off on New Paper asks: “Do journals journals enforce their data policies?”
 I am happy to announce that our paper “Journals in Economic Sciences: Paying Lip Service to Reproducible Research?” finally has been released.
I am happy to announce that our paper “Journals in Economic Sciences: Paying Lip Service to Reproducible Research?” finally has been released.
The article, published in the latest issue of the IASSIST Quarterly, regards the practice of 37 journals in economics and business administration when it comes to the enforcement of their data policies.
For this purpose, we checked 599 articles which have been published in two issues of these journals. We chose the issues 1/2013 and 1/2014.
First, we estimated the share of articles that fall under a data policy, because replication data is needed to verify the published results. Afterwards, we checked the journal data archives and supplemental information section of each of these articles for the availability of replication files.
For a reduced sub-sample of 245 data-based articles, we checked in depth whether the replication files we found are compliant with the requirements of the journal’s respective data policy. Thereby, we are able to determine how much journals in economic sciences enforce their data policies and to calculate the ‘compliance rate’ for each journal in our sample. Read the rest of this entry »
Posted: February 26th, 2018 | Author: Sven | Filed under: Data Policy, Data Sharing | Tags: Replication | Comments Off on Replications in the social sciences: New study confirms ongoing challenges
 Much has been said on the importance of replications. Recently, nature has published another comment that deals with this question. Paul Gertler, Sebastian Galiani and Mauricio Romero (GGR) conducted a survey, in which they focussed on the fields of economics, political science, sociology and psychology. They conclude that ‘the current system makes original authors and replicators antagonists.’
Much has been said on the importance of replications. Recently, nature has published another comment that deals with this question. Paul Gertler, Sebastian Galiani and Mauricio Romero (GGR) conducted a survey, in which they focussed on the fields of economics, political science, sociology and psychology. They conclude that ‘the current system makes original authors and replicators antagonists.’
They found, that in the top-tier economics journals only few articles are replications – and all of those refute the original results. That said, GGR also asked 35 editors and co-editors of these economics journals about their perceptions towards publishing replications. While all editors who responded would publish a study that refutes the original findings, only a fourth can image to publish a study which confirms the original results. Read the rest of this entry »
Posted: January 22nd, 2018 | Author: Sven | Filed under: Data Sharing, found on the net | Tags: Replication, replication studies, reproducibility | Comments Off on KNAW recommends making replication studies a normal and essential part of science
 Over the past few years several systematic series of replication studies have been unable to reproduce many important scientific findings in a whole slew of disciplines. This has led to a debate within the scientific community about the way science is currently being conducted and the role of replication studies. Our blog also published many posts which deal with this question.
Over the past few years several systematic series of replication studies have been unable to reproduce many important scientific findings in a whole slew of disciplines. This has led to a debate within the scientific community about the way science is currently being conducted and the role of replication studies. Our blog also published many posts which deal with this question.
Now, KNAW (the Royal Netherlands Academy of Arts and Sciences) has published a report, which analyses the causes of non-reproducibility, assesses the desirability of replication studies and also offers recommendations for improving reproducibility and for conducting replication studies. Read the rest of this entry »
Posted: January 16th, 2018 | Author: Sven | Filed under: EDaWaX, found on the net | Tags: authority files, linked data | Comments Off on Wikidata as authority linking hub: The examples of RePEc and GND
 From time to time, I post a few more technical oriented articles on this blog. This one is about the opportunities to use Wikidata as an authority linking hub – e.g. for the purpose of correctly identifying authors of scientific publications or data. For developing research infrastructures, it is often is a complex task to offer suitable solutions for a correct identification of an author. Most often it is up to the researchers to correctly indicate their names and to provide a personal identifier (PI), like an ORCID-ID, or a RePEc short-ID.
From time to time, I post a few more technical oriented articles on this blog. This one is about the opportunities to use Wikidata as an authority linking hub – e.g. for the purpose of correctly identifying authors of scientific publications or data. For developing research infrastructures, it is often is a complex task to offer suitable solutions for a correct identification of an author. Most often it is up to the researchers to correctly indicate their names and to provide a personal identifier (PI), like an ORCID-ID, or a RePEc short-ID.
On ZBW labs, my colleague Joachim Neubert a very interesting blog post about connecting such personal identifiers. In particular, he discusses the possibilities to connect researchers’ personal identifiers from the RePEc (Research Papers in Economics) Author Service (RAS) to those of the GND (Integrated Authority File). Read the rest of this entry »
Posted: December 15th, 2017 | Author: Sven | Filed under: found on the net, Report, Research Data | Tags: business model, data repositories, oecd | Comments Off on OECD publishes report on business models for sustainable data repositories
 In 2007, the OECD Principles and Guidelines for Access to Research Data from Public Funding were published and in the intervening period there has been an increasing emphasis on open science. At the same time, the quantity and breadth of research data has massively expanded. The promise of open (research) data is that they will not only accelerate scientific discovery and improve reproducibility, but they will also
In 2007, the OECD Principles and Guidelines for Access to Research Data from Public Funding were published and in the intervening period there has been an increasing emphasis on open science. At the same time, the quantity and breadth of research data has massively expanded. The promise of open (research) data is that they will not only accelerate scientific discovery and improve reproducibility, but they will also
speed up innovation and improve citizen engagement with research.
However, for the benefits of open science and open research data to be realised, these data need to be carefully and sustainably managed so that they can be understood and used by both present and future generations of researchers. Data repositories are where the long-term stewardship of research data takes place and hence they are the foundation of open science. So, the development of sustainable business models for research data repositories needs to be a high priority in all countries. Read the rest of this entry »
Posted: November 30th, 2017 | Author: Sven | Filed under: Report | Tags: infrastructure, Knowledge Exchange, Research Data | Comments Off on New KE-report: ‘The Evolving Landscape of Federated Research Data Infrastructures’
 Knowledge Exchange, a consortium of six national organisations in Europe tasked with developing infrastructures and services to enable the use of digital technologies to improve higher education and research, has just a released a report on federated research data infrastructures.
Knowledge Exchange, a consortium of six national organisations in Europe tasked with developing infrastructures and services to enable the use of digital technologies to improve higher education and research, has just a released a report on federated research data infrastructures.
In 2016, the Knowledge Exchange Research Data expert group identified a need for better understanding of the nature and consequences of research and data infrastructure being more and more federated. Work was designed to find answers to questions such as ‘Which are the main drivers for federating RD infrastructures and services ? What are the expected benefits? What are the consequences for research and researchers? What challenges and issues arise when making a federated research data infrastructure function well?’ Read the rest of this entry »
Posted: September 21st, 2017 | Author: Sven | Filed under: Conference, Workshop | Tags: journals, replication studies | Comments Off on The replication crisis in economics – and how we might answer it
 On September 8, 2017 the ZBW Leibniz Information Center for Economics hosted the workshop “Replications in Empirical Economics – Ways out of the Crisis” at the Annual Conference of the Verein für Socialpolitik in Vienna, Austria. Thirty participants and four speakers engaged in lively and stimulating discussions about replications and the publication of replications in Economics.
On September 8, 2017 the ZBW Leibniz Information Center for Economics hosted the workshop “Replications in Empirical Economics – Ways out of the Crisis” at the Annual Conference of the Verein für Socialpolitik in Vienna, Austria. Thirty participants and four speakers engaged in lively and stimulating discussions about replications and the publication of replications in Economics.
This is a cross-post of the weblog of the replication network. Read the rest of this entry »
Posted: August 7th, 2017 | Author: Timo | Filed under: Report | Tags: economics, repositories, Software, Statistics | Comments Off on Statistical software: its use and popularity in Economics

by Christina Kläre & Timo Borst
During a four weeks project at ZBW’s Department for Information Systems and Publishing Technologies, we collected some publicly available information about statistical software packages being used in research in Economics. This work is inspired by a constantly updated blog post from Robert A. Muenchen, who examined information sources like job announcements, scientific articles, reports from IT companies, questionnaires, sales statistics from software textbooks, blogposts, forums, polls measuring popularity of programming languages, sales and download figures, or the frequency of software releases from software vendors. By means of these sources, we conducted the following data collections. Read the rest of this entry »
Posted: August 1st, 2017 | Author: Sven | Filed under: Data Sharing, journals, Projects | Tags: data journal, Replication, replication studies | Comments Off on Against the replication crisis: New international journal encourages replication studies
Read the rest of this entry »
Posted: July 17th, 2017 | Author: Sven | Filed under: Data Sharing, EDaWaX, journals | Tags: model, research paper | Comments Off on New paper published: “Open access to research data: Strategic delay and the ambiguous welfare effects of mandatory data disclosure”
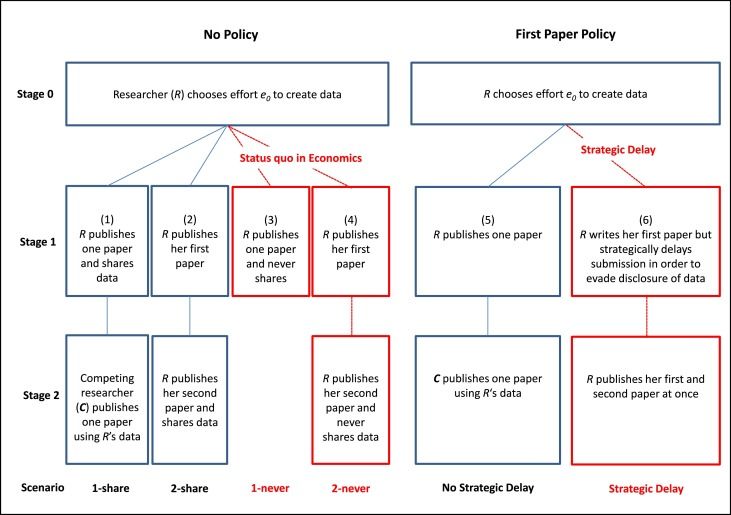 Frank Mueller-Langer and Patrick Andreoli-Versbach have published a new research paper on ‘Strategic delay and the ambiguous welfare effects of mandatory data disclosure’.
Frank Mueller-Langer and Patrick Andreoli-Versbach have published a new research paper on ‘Strategic delay and the ambiguous welfare effects of mandatory data disclosure’.
In the abstract of the paper, the researchers state:
Mandatory disclosure of research data is an essential feature for credible empirical work but comes at a cost: First, authors might invest less in data generation if they are not the full residual claimants of their data after the first journal publication. Second, authors might “strategically delay” the time of submission of papers in order to fully exploit their data in subsequent research. We analyze a three-stage model of publication and data disclosure. We find that the welfare effects of universal mandatory data disclosure are ambiguous. The mere implementation of mandatory data disclosure policies may be welfare-reducing, unless accompanied by appropriate incentives which deter strategic delay.
Read the rest of this entry »
Posted: June 14th, 2017 | Author: Sven | Filed under: found on the net | Tags: data archives, European Commission, infrastructure, social sciences | Comments Off on CESSDA becomes an ERIC
 CESSDA, the Consortium of European Social Science Data Archives, has been established as an ERIC (European Research Infrastructure Consortium) by the European Commission a few days ago. It is the first time in the history of the European Union that a non-member state (Norway) hosts an ERIC.
CESSDA, the Consortium of European Social Science Data Archives, has been established as an ERIC (European Research Infrastructure Consortium) by the European Commission a few days ago. It is the first time in the history of the European Union that a non-member state (Norway) hosts an ERIC.
An ERIC is a specific legal form to facilitate the establishment and operation of research infrastructures with European interest. The principal task of ERIC is to establish and operate new or existing research infrastructures on a non-economic basis. The ERIC becomes a legal entity from the date the Commission decision setting up the ERIC takes effect. Read the rest of this entry »
Posted: May 16th, 2017 | Author: Sven | Filed under: Conference | Tags: AEA, Replication, research paper | Comments Off on American Economic Review publishes AEA’s Session Papers on Replication
 Two weeks ago, the American Economic Review published the ‘Papers and Proceedings‘ of the 129th annual meeting of the American Economic Association (AEA) held in January, 2017.
Two weeks ago, the American Economic Review published the ‘Papers and Proceedings‘ of the 129th annual meeting of the American Economic Association (AEA) held in January, 2017.
At this year’s meeting, one session was dedicated to the topic of ‘Replication in Microeconomics‘ while another focussed on ‘Replication and Ethics in Economics: Thirty Years after Dewald, Thursby, and Anderson“.
In both sessions, very interesting and excellent papers were presented.
Below, I list all presentations of these sessions and the corresponding links to the papers (if available): Read the rest of this entry »
Posted: April 26th, 2017 | Author: Sven | Filed under: found on the net, German, Opinion | Tags: Replication, reproducibility | Comments Off on German Research Foundation (DFG) publishes Statement on Replicability
 The German Research Foundation (DFG) has currently released a statement on the replicability of research results.
The German Research Foundation (DFG) has currently released a statement on the replicability of research results.
Interestingly (at least for me), the five-pager first starts with a broader definition of what replicable research is NOT.
Of course, replication is a very important method for testing empirical knowledge claims based on experimental and quantitative research in medicine, the natural, life, engineering, social and behavioural sciences, as well as the humanities.
But, according to DFG, there are limitations:
- Replicability is not a universal criterion for scientific knowledge.
- Ascertaining the replicability or non-replicability of a scientific result is itself a scientific result. As such, it is not final but subject to methodological scepticism and further investigation.
- Non-replicability is not a universal proof by falsification.
- Non-replicability is not a universal indicator of poor science.
‘Well, an unorthodox starting point for a paper on reproducible research‘ – so, at least, were my thoughts when I read the first page of the statement. Wouldn’t it be more common to first depict the important aspects of reproducible research and to suggest measures to support it, instead of rowing back at the beginning of such a statement? Read the rest of this entry »



